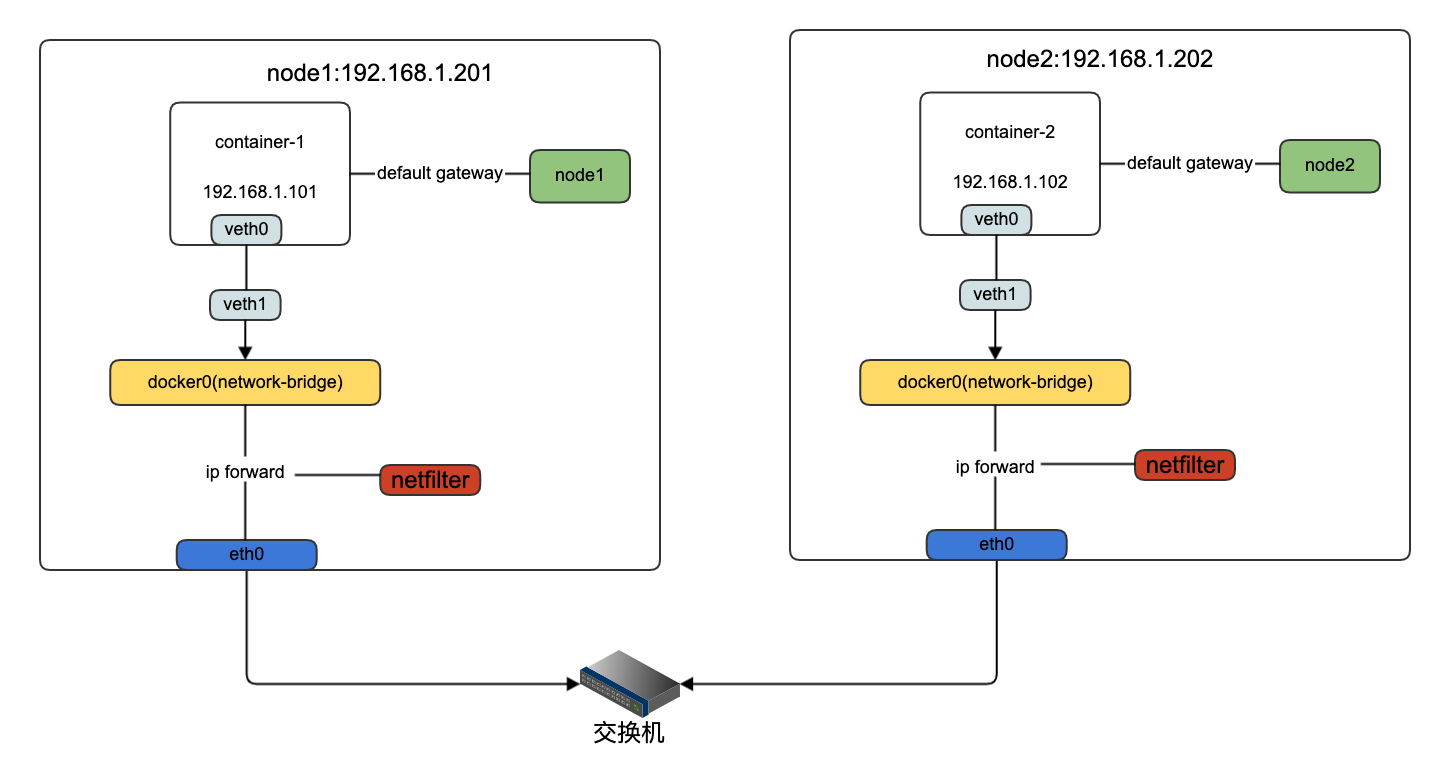
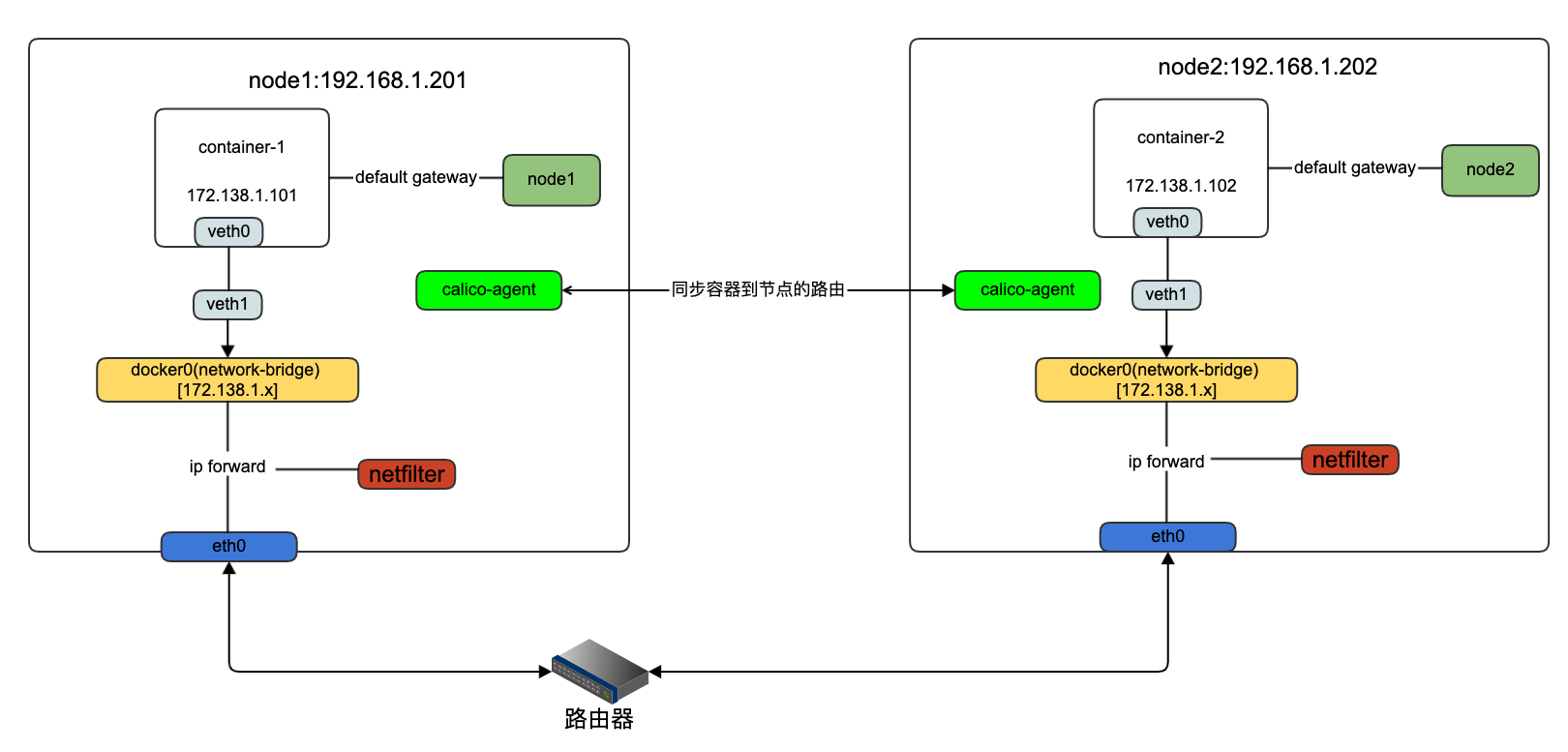
TCP协议初探
发送方对一个ACK应该等待多长时间?
如果ACK丢失怎么办?
- 如果一个ack丢失了,发送方式是不能轻易的识别ACK丢失和原分组的丢失的情况,所以发送方会再次发送原分组
如果分组被接受了,但是分组有错误怎么办?
- 使用编码技术检测一个大的分组的差错一般都是简单,仅仅使用比自身小很多的一些比特即可纠正。当接受方接受到有差错的分组,接收方是不能发送ACK,最后发送方重新发送无差错的分组
如果接受方接收到了重复分组怎么办?
- 发送方针对每个分组会有一个序列号,这个序列号是有分组自身携带,接受方可以使用这个序列号来判断它是否已经接受到这个分组,如果是则丢弃
什么是分组窗口和滑动窗口?
- 定义一个分组窗口作为已经被发送方发送但还没完成收到ACK确认的分组的集合,这是分组窗口;这个分组窗口的数量叫做窗口大小;发送方和接受方都存在滑动窗口,对于发送方,滑动窗口记录发送已确认的分组(可释放)、发送未收到确认的分组、即将发送的分组。对于接收方,滑动窗口记录已接受和确认的分组、期望接受分组、即将接受可能因为内存限制而被丢弃的分组。
什么是流量控制和拥塞控制?
- 在接受方接受分组的速度跟不上发送方发分送分组的速度,会强迫发送方把发送分组的速度降下来,这个称谓流量控制;流量控制有2种方式,一种是基于速率,它给发送方指定某个发送的速率,同时确保数据永远不会超过这个发送速率发送,这个仅仅适合流应用程序,可用于广播和组播。另外一种是基于窗口流量控制,是使用滑动窗口,在这个方法里,滑动窗口大小不固定,随着时间而变化。必须有一种方法让接受方可以通知发送方应该使用多大的滑动窗口,这个接受方通知发送方的窗口叫做窗口更新。
- 在发送方和接受方之间可能会有因为有限内存的路由器,它们和低速网络链路抗争着,当这种情况发生时候,发送方发送分组的速率可能超过某个路由器的能力,从而导致丢包,这种情况是有拥塞控制的流量控制方式来处理。拥塞控制涉及发送方降低发送速度,不至于压垮其和接受方之间的网络。
如果设置重传超时?
- 发送方在重发一个分组之前等待的时间包括:发送分组所用时间、接受方处理分组时间、接受方发送ACK的时间、发送方接受ACK所用时间。在这些时间都是不确定的。比较好的策略让协议实现尝试去评估它们,这称为往返时间评估,这是一个统计过程。
TCP服务有什么特点?
- TCCP虽然TCP和UDP都使用相同的网络层(IP层),但是TCP给应用程序提供一种和UDP完全不同的服务,TCP提供一种面向连接、可靠的字节流的服务,面向连接是指TCP的两个应用程序必须在他们可交换数据之前,通过相互联系来建立一个TCP连接。最经典的比喻,拨打一个电话号码,等待另外一方接电话并说“喂”,然后说“找谁?”,这正是一个TCP连接的两个端点之间的通信,广播和组播不存在于TCP,存在于UDP。
- TCP没有消息边界,是一种流式服务。
TCP如何保证可靠性?
- TCP提供一个字节流接口,TCP必须把一个发送应用程序的数据转换为一组IP可以携带的分组,这个分组叫做组包,这些分组包含序列号,这个序列号实际代表每个分组的第一个字节在整个应用程序数据中的字节偏移量,而不是分组号。
- TCP传给IP层的块叫做报文段,应用程序数据被打散成TCP人为最佳的大小块来发送,使得每个报文段按照不会被IP层数据报的大小来划分
- TCP发送一组报文段时会设置一个重传计时器,等待对方的确认接收,TCP不会为每个报文段设置一个不同的重传计时器,相反,发送一个窗口的数据,它仅仅设置一个计时器,当ACK到达时候在更新计时器;如果ACK么有及时接收,这个报文段会被重传。
- 当TCP接收到连接的另一端数据时候,它会发送一个ACK确认给另一端,告知另一端数据已经接受。这个ACK确认可能不会立即发送,一般会延迟发送。
- TCP给应用程序提供一种双工服务,数据可以在两个方向上流动,两个方向互相独立,因此连接的每个端点必须对每个方向维持一个数据流的一个序列号,一旦建立一个连接,这连接的一个方向上的包含数据流的每个TCP报文段也包含了相反方向上的报文段的一个ACK。
- TCP接受端使用序列号来丢弃重复的报文段和记录杂乱次序到达的报文段,TCP使用IP来传递它的报文段,IP不提供重复消除、保证次序正确的功能。然而,因为TCP是一个字节流协议,TCP绝不会以杂乱次序给接收应用程序发送数据,因此TCP接收端可能会被迫先保持大序列号的数据不交给应用程序,知道缺失的小序列号的报文段被填满。
TCP头部和封装是什么样的?
- 每个TCP头部都包含源和目标的端口,这两个值和IP头部的源和目标IP地址一起唯一的标识每个连接,TCP术语中,一个IP地址和一个端口的组合有时被称为套接字或者端点。每个TCP连接由一对套接字或端点(四元组,客户端IP、客户端端口、服务器IP,服务器端口唯一标识。
- 确认字段(ack)包含德玛值是该确认号发送方期待接受下一个序列号,即最后发送成功的数据字节的序列号加1
- 当建立一个新连接时,从客户机发送至服务器的第一个报文段的SYN位字段被启用,这个报文段称为SYNC报文段