System IO
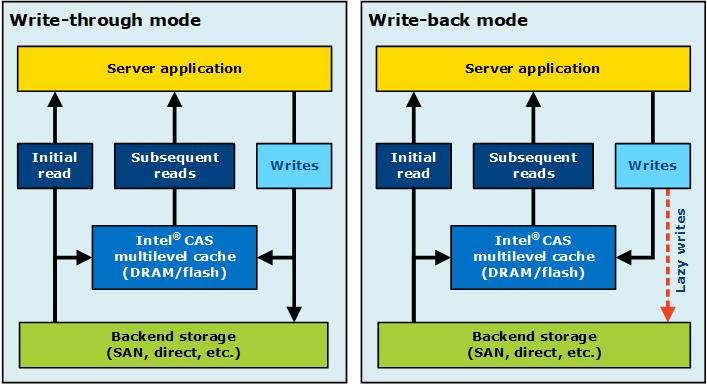
- System IO指的是使用open/close/read/write/lseek系统调用使用io的方式,这样的方式是实打实的从user space->kernel space中函数调用,这样的方式是实时性高。
Standard IO
- Standard IO 是是指使用stdio中的FILE中的fopen/fclose/fread/fwrite/fseek等方式进行IO的操作.使用stdio中的函数实现是依赖底层system io的系统函数。stdio中的函数是带有cache的机制,说简单点就是merge system io函数的调用,已达到在kernel层面减少系统调用的,这样的IO方式可以提高吞吐量。
文件描述符本质

每个文件open/fopen以后会产生一个inode-struct.一个inode-struct包含了文件操作的基本属性以及position,position是这个文件读写的位置。每个inode-struct会保存在每个进程中的文件描述符的数组中,open返回的fd就是这个数组的下边。
每个进程在默认情况下最多打开1024个文件描述符,0/1/2默认是是输入、输出、错误输出。
进程中文件描述符数组使用方式按照最小下标方式。
FILE 结构中的position和inode-struct中的postition基本不是一样的,这个为什么?比如执行三次fput(FILE,’a’),这样的操作在FILE结构中postion会++3次。这个position中是揍batch然后在kernel层面统一执行一次系统调用。
System IO 和 Standard IO 不能混用。
验证推断
实例代码验证standard io缓冲以及system io 实打实的调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22/*************************************************************************
> File Name: test.c
> Author:perrynzhou
> Mail:perrynzhou@gmail.com
> Created Time: Sat May 4 21:58:45 2019
************************************************************************/
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
putchar('a');
write(1, "b", 1);
putchar('a');
write(1, "b", 1);
putchar('a');
write(1, "b", 1);
exit(0);
}执行结果如下

trace下test执行路径

分析
strace后的执行路径,可以看出,putchar执行三次最后是一次write(1,”aaa”,3)写入。其他的关于b的写入,每一次write都会写一次。